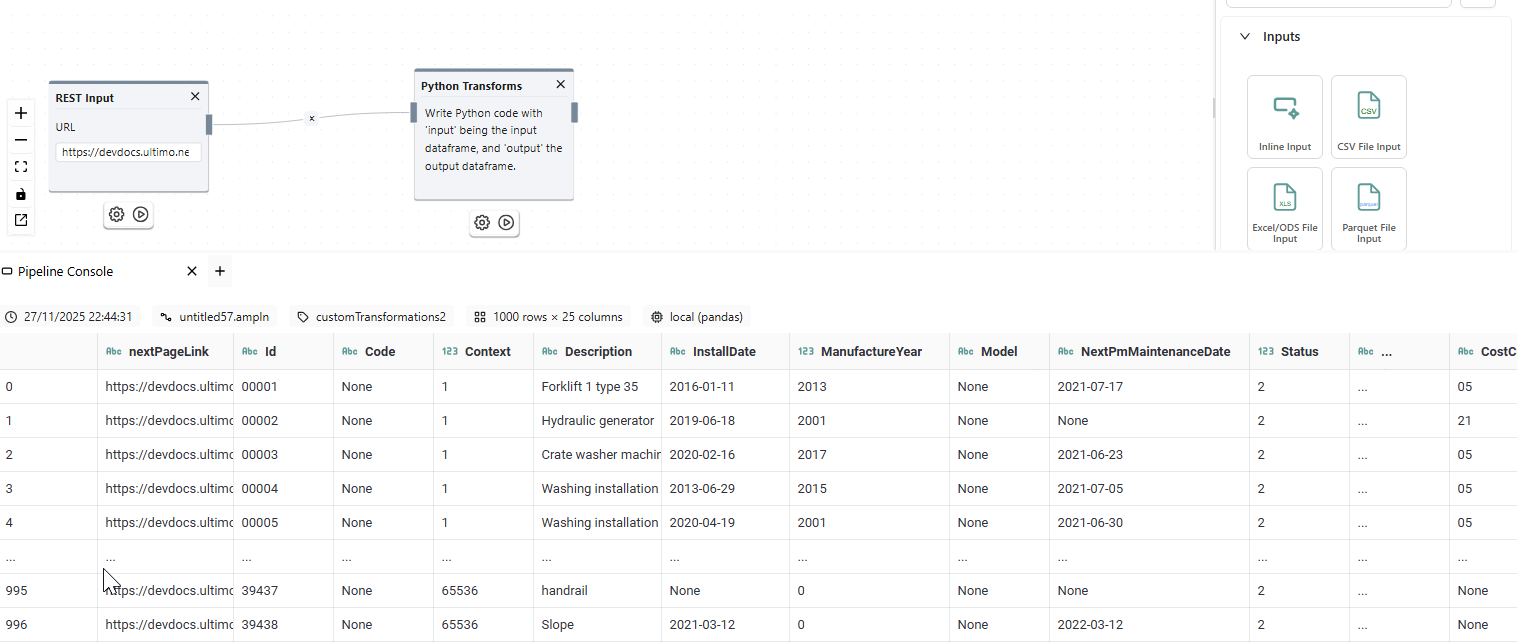
Hi,
i’m getting json output out of a GET request. Maybe i’m missing something but it is unable for me to explode the arrays into rows.
Can someone help me?

Thanks!
Hi,
i’m getting json output out of a GET request. Maybe i’m missing something but it is unable for me to explode the arrays into rows.
Can someone help me?
Thanks!
Hello @harmenkuijer
Can you please share
-the version of Amphi you’re using ?
-the json (of an example of it) you’re trying to explode in plain text (so that we can have a look to reproduce) ?
Best regards,
Simon
Hi Simon,
thanks for your reply. I’m using the latest version of Amphi. Here you wil find an example output:
{
"items": [
{
"Id": "000811",
"Code": null,
"Context": 65536,
"CurrentMaintenanceStateDate": null,
"DataProvider": null,
"Description": "*******************",
"ExternalId": "E000811",
"GeocodeX": 0.0000000000,
"GeocodeY": 0.0000000000,
"InstallDate": null,
"ManufactureYear": 0,
"Status": 2,
"RiskScore": 0.00,
"Text1": "*******************",
"CostCenter": null,
"CurrentMaintenanceState": null,
"EquipmentType": null,
"Manufacturer": null,
"MaintenanceState": null,
"PartOfEquipment": null,
"ProcessFunction": "000241",
"ProgressStatus": null,
"Site": "D",
"Vendor": null
},
{
"Id": "000812",
"Code": null,
"Context": 32768,
"CurrentMaintenanceStateDate": null,
"DataProvider": null,
"Description": "*******************",
"ExternalId": "E000812",
"GeocodeX": 0.0000000000,
"GeocodeY": 0.0000000000,
"InstallDate": null,
"ManufactureYear": 0,
"Status": 2,
"RiskScore": 0.00,
"Text1": '*******************',
"CostCenter": null,
"CurrentMaintenanceState": null,
"EquipmentType": "00703",
"Manufacturer": null,
"MaintenanceState": null,
"PartOfEquipment": "000811",
"ProcessFunction": "000241",
"ProgressStatus": "USEQM0203",
"Site": "D",
"Vendor": null
},
{
"Id": "000813",
"Code": null,
"Context": 32768,
"CurrentMaintenanceStateDate": null,
"DataProvider": null,
"Description": "",
"ExternalId": "E000813",
"GeocodeX": 0.0000000000,
"GeocodeY": 0.0000000000,
"InstallDate": null,
"ManufactureYear": 0,
"Status": 2,
"RiskScore": 0.00,
"Text1": '*******************',
"CostCenter": null,
"CurrentMaintenanceState": null,
"EquipmentType": "00703",
"Manufacturer": null,
"MaintenanceState": null,
"PartOfEquipment": "000811",
"ProcessFunction": "000241",
"ProgressStatus": "USEQM0203",
"Site": "D",
"Vendor": null
}
]
}
Hello @harmenkuijer
Have you noticed there is single quote around Text1 value1 (instead of quotes)?
But even with that typo solved, yes, there is an issue
For furrther reference https://devdocs.ultimo.net/api/v1/object/Equipment?ApiKey=BED9194293084F68807042B9451B36D0
Can you try this in a python transform?
def flatten_json_column(
df: pd.DataFrame,
json_col: str,
max_level=None,
sep=“.”,
keep_columns=True,
flatten_array_direction=“row”, # “row” (default) or “column”
):
“”"
Flatten a column containing JSON objects or strings into a DataFrame.
Handles nested dicts and arrays, producing either multiple rows or columns.
“”"
def _flatten(obj, parent_key="", level=1):
"""Recursively flatten dicts and lists."""
items = []
if isinstance(obj, dict):
for k, v in obj.items():
new_key = f"{parent_key}{sep}{k}" if parent_key and keep_columns else k
if isinstance(v, dict) and (max_level is None or level < max_level):
items.extend(_flatten(v, new_key, level + 1))
elif isinstance(v, list) and (max_level is None or level < max_level):
if flatten_array_direction == "column":
# Expand list into numbered columns
for i, elem in enumerate(v):
if isinstance(elem, (dict, list)):
items.extend(_flatten(elem, f"{new_key}{sep}{i}", level + 1))
else:
items.append((f"{new_key}{sep}{i}", elem))
else:
# Row direction: expand into multiple rows (later)
items.append((new_key, v))
else:
items.append((new_key, v))
else:
# Not a dict: just return the object as value
items.append((parent_key, obj))
return items
def _expand_rows(base_row):
"""Handle array-to-row expansion for row mode."""
array_keys = [k for k, v in base_row.items() if isinstance(v, list)]
if not array_keys:
return [base_row]
# Create Cartesian product of all array elements
array_values = [base_row[k] for k in array_keys]
combinations = product(*array_values)
expanded = []
for combo in combinations:
new_row = base_row.copy()
for k, val in zip(array_keys, combo):
if isinstance(val, dict):
for sub_k, sub_v in _flatten(val, k):
new_row[sub_k] = sub_v
else:
new_row[k] = val
# Remove list-type columns after expansion
for k in array_keys:
if isinstance(new_row.get(k), list):
del new_row[k]
expanded.append(new_row)
return expanded
all_rows = []
for _, row in df.iterrows():
raw = row[json_col]
if isinstance(raw, str):
try:
data = json.loads(raw)
except json.JSONDecodeError:
continue
else:
data = raw
flat_items = dict(_flatten(data))
base_rows = [flat_items]
# Expand arrays into rows if needed
if flatten_array_direction == "row":
new_rows = []
for br in base_rows:
new_rows.extend(_expand_rows(br))
base_rows = new_rows
# Merge with other columns
for br in base_rows:
combined = row.drop(labels=[json_col]).to_dict()
combined.update(br)
all_rows.append(combined)
return pd.DataFrame(all_rows)
output = flatten_json_column(
df=input,
json_col=“items”,
max_level=None,
sep=“.”,
keep_columns=True,
flatten_array_direction=“row”
)
not perfect (I have object, not string) but should be way better.
Edit: also tried to expand the code with the given ‘before’ and ‘after’ code. But still not working.
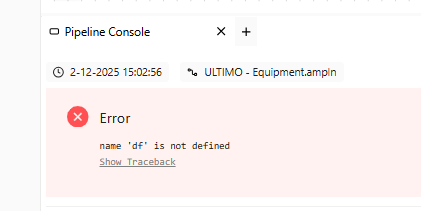
While using only your generated code I get the ‘df is not defined’ error. Can you give me the complete code from your transformer? I think a copy/paste error has occured.
@harmenkuijer Sorry, the copy-pasta killed the code, especially the indentation. I put it on github here but still have some issues on it… ![]()
Used a Python transformer with the following code:
output = input.explode('data').reset_index(drop=True)
output = pd.concat([
output.drop('data', axis=1),
output['data'].apply(pd.Series)
], axis=1)
output = output.drop(columns=['data'], errors='ignore')